
From Software Engineer to AI Builder: A Practical Guide
TL;DR FAQ: Can You Move From Software Engineering Into AI Without Starting Over?
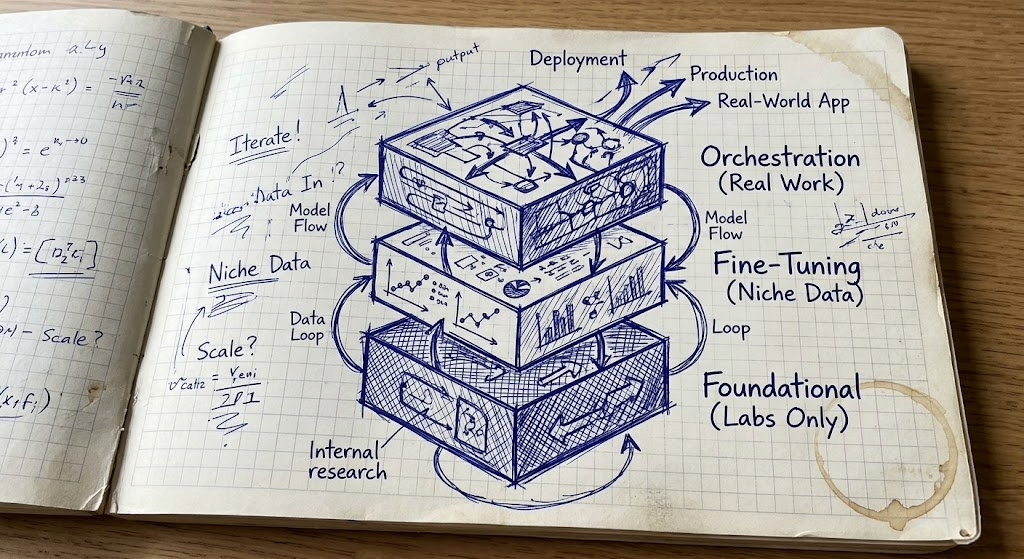
▼ Q: What is the AI engineering stack and why does it matter for career changers?
A: The AI engineering stack has three layers: orchestration (building agent systems using tools like LangChain, LangGraph, and MCP), fine-tuning (adapting models on proprietary data using techniques like QLoRA), and foundational research (training models from scratch at labs like Anthropic and OpenAI). Most new jobs are at Layer 1, which means software engineers can enter the field without retraining from the ground up.
▼ Q: Do I need a machine learning background to get an AI engineering job in 2026?
A: Not for most roles. Layer 1 orchestration work requires Python fluency, a working understanding of vector embeddings, and hands-on experience prompting current frontier models like GPT-5.4, Claude Sonnet 4.6, or the open-weight Llama 4. Engineers who have spent years building REST APIs or designing distributed systems already have the foundation. The learning curve is real but it is measured in weeks, not years.
▼ Q: What is the difference between building AI agents for a product team versus an internal IT team?
A: Product teams optimize for latency, scale, and reliability at volume. An agent that fails 5 percent of the time is a customer retention problem. Internal enterprise teams prioritize data governance and compliance: sensitive HR, finance, and legal data cannot pass through an external model’s context window uncontrolled. The tools overlap, but the success criteria and risk profiles are fundamentally different. KPMG’s 2026 AI Pulse Survey found that system complexity and governance are now the top deployment challenges as organizations scale from prototypes to production.
▼ Q: What is QLoRA and why do AI engineers need to know it?
A: QLoRA is the practical standard for fine-tuning large language models without enterprise-scale compute budgets. It loads a base model in compressed 4-bit format and trains lightweight adapter layers on top, making it possible to fine-tune a 65-billion parameter model on a single GPU. For data scientists and ML engineers moving into Layer 2 work, QLoRA is the entry point to model adaptation. Open-weight models like Llama 4 and DeepSeek-V3.2 have made this even more accessible, with 85 percent of organizations in a recent NVIDIA survey calling open-source models moderately to extremely important to their AI strategy.
▼ Q: Which background transitions most naturally into each layer of the AI stack?
A: Software and product engineers transition most naturally into Layer 1 orchestration. Data scientists and ML engineers are best positioned for Layer 2 fine-tuning and model adaptation. Foundational research at Layer 3 remains largely the domain of PhD-level researchers at major labs. SaaS architects and CTOs are well positioned to lead cross-layer strategy without needing to specialize in any single tier. Deloitte’s 2026 enterprise AI report found that insufficient worker skills are the single biggest barrier to AI integration, meaning organizations are actively looking for engineers who can bridge these layers.
▼ Q: What should a CTO actually do about AI in 2026?
A: Avoid building at Layer 3. Paying to train foundational models when Anthropic and OpenAI already do it is the wrong investment for most organizations. The real priority is building evaluation infrastructure that can detect when an agent is failing in production, because AI failure modes are not compiler errors. They are subtle reasoning failures that only surface at scale. Only one in five companies currently has a mature governance model for agentic AI, according to Deloitte, making that the most urgent gap for technology leaders to close.
▼ Q: How large is the market for agentic AI and why does it matter for hiring?
A: Multiple research firms now project the global agentic AI market will exceed 139 to 199 billion dollars by 2034, up from roughly 7 to 10 billion dollars today. Gartner estimates 40 percent of enterprise applications will include task-specific agents by end of 2026, up from less than 5 percent in 2025. March 2026 data shows 72 percent of Global 2000 companies have already moved AI agents beyond pilot programs into production. Demand for engineers who can build and operate these systems is outpacing supply at every layer of the stack.
Some people think “building AI” means you have to be able to train neural networks in a research lab.
It doesn’t.
The field has split into three distinct layers, and two of them are wide open to people who already write code for a living.
The Three Layers
Layer 1: Orchestration
This is where most of the new jobs are. You are not training a model here. You are building systems that use models to get real work done.
Think about the difference between a chatbot that answers a question and an agent that reads your inbox, finds emails from a specific client, drafts replies based on past correspondence, and queues them for your review. Building that second thing is an orchestration problem.
The core work is three things: RAG pipelines so models can pull in fresh data at runtime, tool-calling so a model can actually do something like query a database, and memory management so a ten-step agent doesn’t forget what it decided in step three.
The hardest constraint here is not intelligence. It is reliability and speed.
Frameworks split into two camps. Python options like LangChain and LangGraph are easier to start with. Rust-based frameworks like AutoAgents are faster, with cold starts around 4 milliseconds compared to 60-plus for Python, and use a fraction of the memory. At high volume, that gap is the difference between a system that scales and one that doesn’t.
The glue connecting agents to external data is the Model Context Protocol (MCP), an open standard that lets any agent talk to any data provider without custom integration code for every combination. One critical pattern: instead of loading every tool definition into the model’s context upfront, agents write small scripts on demand to query what they need. Token costs stay down. Sensitive data stays off the context window.
Layer 2: Fine-Tuning and Model Adaptation
This is where models get shaped for specific jobs.
A general-purpose model knows a lot. It doesn’t know your company’s legal review standards or your internal product taxonomy. That’s what refiners fix.
The work is fine-tuning models on proprietary datasets, compressing them through quantization so they run on cheaper hardware, and building evaluation systems to prove the model is actually improving.
The biggest obstacle is data quality. Assembling 50,000 clean, correctly labeled examples of how a model should behave in a medical documentation context is slow and expensive. Automated pipelines help: the model generates improved training examples, judges its own outputs, keeps the better ones, and discards the rest.
Full fine-tuning on a large model is prohibitively expensive for most organizations. The practical standard is QLoRA, which loads the base model in compressed 4-bit format and trains small adapter layers on top. A 65-billion parameter model, fine-tuned on a single GPU a startup can actually afford to rent. The current best-practice configuration pairs QLoRA with DoRA applied across all linear layers, which consistently outperforms the original default of targeting only attention layers.
Layer 3: Foundational Research
This layer is occupied almost entirely by Anthropic, OpenAI, Meta, and Google.
The work involves designing new architectures, managing clusters of 10,000 or more GPUs, and running training jobs that last four months or longer. At the scale of 20,000 GPUs in parallel, hardware failures are not rare events. They are daily occurrences. Network overhead alone can drop actual GPU utilization to fifty percent, meaning half of a multi-million-dollar infrastructure budget sits idle waiting for data.
Most organizations will never touch this layer. And they shouldn’t try.
Where You Fit In
If You Write Code Today
CS student: Build something real before you graduate. An agent that scrapes a job board, matches postings to a resume, and drafts outreach emails will teach you more than any course. RAG, tool calling, prompt engineering, latency debugging: all of it, hands on. The students standing out right now are not the ones who can recite attention math. They are the ones who have shipped something that actually runs.
Product engineer: Your instincts about system design, API contracts, and reliability translate directly to Layer 1. The adjustment is accepting probabilistic behavior. An agent that succeeds 95 percent of the time is not broken in the way a function returning the wrong value 5 percent of the time is broken. Debugging requires trace-level logging where every step of an agent’s reasoning is recorded. A backend engineer who has spent years writing REST APIs can be building production-ready agents in weeks. The failure modes that kill products are not bad models. They are agents that silently take the wrong action at scale.
Internal IT or enterprise developer: You are building for a different set of constraints. Your users are colleagues, not customers. Your tolerance for latency is higher, but your tolerance for data leakage is lower. An HR agent touching employee records or a finance agent querying internal reporting systems share one requirement: sensitive data cannot pass through an external model’s context window uncontrolled. That MCP pattern mentioned above is not a performance optimization here. It is a compliance requirement. Getting governance and audit trails right from the start is what separates a proof of concept from something that actually reaches production.
SaaS architect: The interesting problems here are systemic. How do you wire a fine-tuned model into an orchestration pipeline without creating a brittle integration that breaks every time the model updates? How do you version prompt templates the way you version code? Gartner estimates 40 percent of enterprise applications will include task-specific agents by end of 2026, up from less than 5 percent last year. That inflection point is an architecture problem as much as it is an AI problem.
If You Work With Data or Models Today
Data scientist: Layer 2 fits your background better than you might expect. You already think in distributions, care about statistical significance, and have healthy skepticism about data quality. The shift is applying that rigor to training pipelines instead of dashboards. A data scientist who spent years cleaning clickstream data for a recommendation engine already has the instincts this layer demands. Add MLOps tooling, Docker, and some GPU profiling practice, and you are positioned for fine-tuning work professionally.
ML engineer: You are already native to Layer 2. The work is applying LoRA and QLoRA adapters, running quantization to make large models fit on affordable hardware, and operationalizing pipelines using tools like MLflow or Kubeflow. The growth edge from here is evaluation: building systems that prove a fine-tuned model is genuinely better and not just overfitting to your training set.
Academic researcher: Layer 3 demands work that is both mathematically rigorous and efficient enough to run on bare metal at scale. A researcher who can prove a theorem but cannot profile a CUDA kernel is not ready. Hardware failures are daily. Network overhead is brutal. The transition means caring as much about synchronization and fault tolerance as about the math behind the architecture.
If You Lead Teams or Set Direction
CTO: The strategic question is which layers to invest in and which to buy.
Building at Layer 3 is almost certainly not the answer. Paying for foundational model training when Anthropic and OpenAI are already doing it is like building your own database engine when Postgres exists.
Layer 1 is where product differentiation actually happens. The agent that reliably completes a twenty-step procurement workflow beats the one backed by a marginally better base model every time. Your real job is making sure your engineering organization has the evaluation infrastructure to know when an agent is ready for production. The failure modes are not compiler errors. They are subtle reasoning failures that only surface at scale.
The engineers who will do well are not necessarily the ones who understand the most transformer math. They are the ones who can build systems reliable enough to trust with real work.
The market is moving fast. A survey of over 1,300 AI practitioners found that 57 percent of organizations already have agents running in production. As of March 2026, 72 percent of Global 2000 companies have moved beyond pilots into operational deployments. Multiple research firms project the global agentic AI market will grow from roughly 9 billion dollars today to somewhere between 139 and 199 billion dollars by 2034. If you can already build reliable software, you are closer to this market than you think.
How STEM Search Group Can Help
The demand for engineers who understand this stack is outpacing supply fast.
STEM Search Group specializes in placing technical talent across all three layers: the orchestration engineers building production agent systems, the ML specialists fine-tuning models for vertical applications, and the senior architects who know how to connect the two.
Whether you are a company trying to hire your first AI engineer or a technical professional ready to make the move into this space, STEM Search Group has the network and the domain knowledge to make the right match.
Reach out to start the conversation.
Sources
- https://futransolutions.com/blog/beyond-chatbots-why-2026-is-the-year-of-frontier-agents/
- https://blog.dataopslabs.com/the-2026-enterprise-frontier-mastering-agentic-ai-workflows-my-understanding
- https://www.speakeasy.com/blog/ai-agent-framework-comparison
- https://dev.to/saivishwak/benchmarking-ai-agent-frameworks-in-2026-autoagents-rust-vs-langchain-langgraph-llamaindex-338f
- https://modelcontextprotocol.io/specification/2025-03-26
- https://cloud.google.com/discover/what-is-model-context-protocol
- https://devstarsj.github.io/2026/03/18/model-context-protocol-mcp-complete-guide-2026/
- https://www.anthropic.com/engineering/code-execution-with-mcp
- https://medium.com/@mlops_playbook/fine-tuning-large-language-models-made-easy-a-practical-guide-to-lora-qlora-peft-590dc36179dd
- https://huggingface.co/docs/peft/developer_guides/quantization
- https://huggingface.co/docs/peft/developer_guides/lora
- https://huggingface.co/papers/2309.14717
- https://arxiv.org/html/2403.12776v1
- https://arxiv.org/html/2508.01543v2
- https://www.together.ai/blog/multi-node-gpu-training
- https://huggingface.co/docs/bitsandbytes/fsdp_qlora
- https://huggingface.co/spaces/nanotron/ultrascale-playbook
- https://arxiv.org/html/2401.02643v1
- https://getdx.com/blog/ai-engineer-vs-software-engineer/
- https://dev.to/klement_gunndu/the-ai-engineering-stack-in-2026-what-to-learn-first-1nhj
- https://aimagazine.com/news/embracing-the-era-of-the-agentic-enterprise
- https://andriifurmanets.com/blogs/ai-agents-2026-practical-architecture-tools-memory-evals-guardrails
- https://www.confident-ai.com/blog/definitive-ai-agent-evaluation-guide
- https://www.gartner.com/en/newsroom/press-releases/2025-08-26-gartner-predicts-40-percent-of-enterprise-apps-will-feature-task-specific-ai-agents-by-2026-up-from-less-than-5-percent-in-2025
- https://www.deloitte.com/us/en/what-we-do/capabilities/applied-artificial-intelligence/content/state-of-ai-in-the-enterprise.html
- https://www.vktr.com/ai-technology/wiring-the-intelligent-enterprise-for-the-year-ahead-2026-will-be-a-year-of-reckoning-for-ai/
- https://www.spectrocloud.com/blog/enterprise-ai-2026-trends
- https://www.informatica.com/resources/articles/enterprise-ai-agent-engineering.html