
Prompt Engineering Is Not Dead. It Just Found Its Place.
TL;DR FAQ: Is Prompt Engineering Dead — or Did It Just Evolve?
▼ Q: Is prompt engineering actually dead?
A: No. The job title “Prompt Engineer” may be fading, but the skill is foundational. What’s changed is the scope — organizations have matured from simply talking to AI models toward engineering real-world outcomes at scale. Prompting was never the destination; it was the first layer of a much larger system.
▼ Q: What are the five layers of an AI system that actually works?
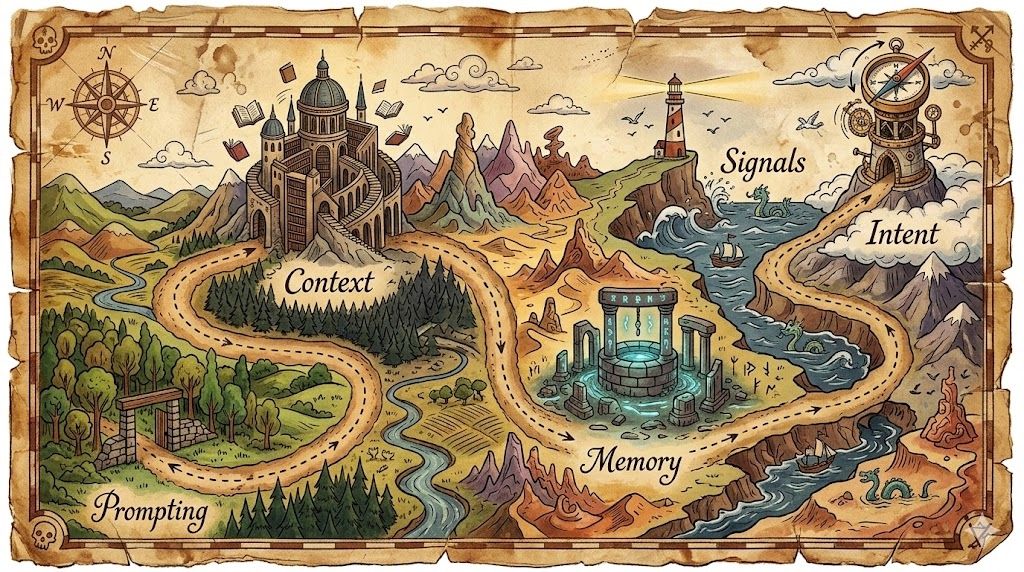
A: The five layers are Prompting (how instructions are given), Context (what information the system can access right now), Memory (what the system retains across time), Signals (what the system monitors to understand reality), and Intent (the control loop that defines and verifies success). Most companies are still operating only at layer one.
▼ Q: Why does prompting still matter if AI models are smarter now?
A: Better models make weak thinking easier to hide — not irrelevant. Vague prompts let the model fill gaps with confident-but-wrong answers, quiet assumptions, and results that technically follow instructions but fail the actual task. Rigorous teams treat prompts like scientific hypotheses: they rewrite them, test alternative framings, and verify whether conclusions hold across versions.
▼ Q: What is content engineering, and how does it differ from prompt engineering?
A: Prompt engineering focuses on how instructions are given to an AI model. Content engineering goes a layer deeper — it’s about structuring, curating, and governing the information the system draws from to generate responses. Where prompting shapes the ask, content engineering shapes the knowledge base behind the answer, including which sources are trusted, how fresh they are, and how they’re retrieved.
▼ Q: What is intent engineering, and how does it differ from prompt engineering and content engineering?
A: Prompt engineering defines how you ask. Content engineering defines what the system knows. Intent engineering defines what success actually looks like — and builds a control loop to verify it. It treats outcomes as something you define, measure, and improve over time, not something you hope emerges from a well-worded prompt or a clean retrieval. It’s the difference between a demo that produces output and a production system that delivers results and can explain when it fails.
▼ Q: What are AI signals, and what are the different types?
A: Signals are what an AI system monitors to understand reality — the inputs it uses to detect patterns, opportunities, and changes in the world. They mature across four stages: Commodity signals are purchased lists and aggregated feeds available to everyone; Derived signals are insights computed from public data like job postings, patents, and filings; First-party signals are internal metrics only your organization has, such as usage data, pipeline performance, and operations; and Engineered signals combine multiple datasets with domain logic tied to specific outcomes. The first two categories are table stakes. Defensible competitive advantage lives almost entirely in the last one.
▼ Q: What consistently breaks AI systems in real-world production?
A: The most common failure modes are wrong retrieval with a confident answer, stale internal documentation that agents keep citing, outputs that look clean but fail audit, edge case collapse under pressure, and fragile operators who can run the system but can’t diagnose it when something goes wrong. The fix isn’t slowing adoption — it’s building teams with both domain knowledge and systems fluency.
▼ Q: What kind of talent actually has an advantage in an AI-driven workplace?
A: The advantage goes to professionals who think in systems, not just tasks. The most valuable people can turn a messy request into something testable, distinguish analysis from bias introduced by question framing, and define what to measure week over week to confirm a system is improving — not just producing more output.
▼ Q: What is spec-driven development for AI agents, and why does it matter?
A: Spec-driven development means building AI agents against explicit, written specifications rather than intuition or “it seems to work” feedback. A solid agent spec defines intent, trusted inputs, hard constraints, available tools, verification checks, and failure behavior. Teams that skip this step end up with inconsistent agents — because if an agent can’t be tested, it can’t be trusted.
Every few months, someone buries something either because of or tied to AI. Prompt engineering is the latest casualty, replaced allegedly by “content engineering.”
Here’s what those obituaries miss: the job title “Prompt Engineer” might be fading. The skill isn’t. It’s foundational.
Prompting was never the destination. It was the first brick. What’s actually happening beneath the hype is a maturation. We’re shifting from simply talking to models toward engineering outcomes that hold up in the real world, under real pressure, at scale.
The organizations getting this right aren’t just prompting better. They’re building systems. And those systems rest on five layers worth understanding, whether you’ve been training models for years or just started wondering what AI actually means for your business.
The Five Layers of an AI System That Actually Works
Think of it like a management structure, or a control system, depending on your background. Either way, most companies are still stuck on layer one.
▸ Prompting — How instructions are given
▸ Context — What information the system can use
▸ Memory — What the system retains over time
▸ Signals — What the system watches to understand reality
▸ Intent — The control loop that defines success and verifies results
Layer 1: Prompting — The First Brick
Models are better now. Sloppy prompts sometimes “work.” That doesn’t make prompting irrelevant. It just makes weak thinking easier to hide.
When instructions are vague, the model fills in the gaps. That’s where you get confident answers that are wrong, quiet assumptions baked into outputs, and results that technically follow the prompt but fail the actual task.
Good prompting comes down to three questions:
- What outcome are we actually trying to achieve?
- What constraints matter here?
- What does success look like, and how would we know if we had it?
One thing that doesn’t get enough attention: prompts can introduce bias. Not “bias” in the abstract, but bias through framing. Ask a leading question, narrow the options, bake an assumption into the setup, and you’ve already steered the result before analysis even begins.
The most rigorous teams treat prompts like scientific hypotheses. They rewrite them, test alternative framings, and verify whether conclusions hold across versions.
Layer 2: Context — What the System Knows Right Now
Prompting tells the system what to do. Context determines what it knows while doing it.
Models are trained on broad, frozen snapshots of the world. Real work runs on current information, proprietary knowledge, and domain-specific facts. That’s why retrieval-based patterns matter: pull trusted material first, then generate from it.
The upside is control and auditability. The downside is that context becomes its own system with its own failure modes. Wrong documents get retrieved. Outdated policies slip through. A single messy source can contaminate the answer.
If you’re serious about production, context needs rules: trusted sources, freshness thresholds, access controls, traceability. Without them, you’re not building a system. You’re hoping.
Layer 3: Memory — What the System Keeps Over Time
Context makes a single answer better. Memory makes an agent useful across days and weeks.
Once you move from one-off Q&A to agents executing multi-step work, memory becomes load-bearing:
- Short-term — what’s in the current interaction
- Semantic — what it can “recall” through vector search
- Structured — key facts it should never guess at: rules, budgets, constraints, preferences
Memory isn’t “store everything.” It’s deciding what gets saved, what gets retrieved, what counts as ground truth, and what gets forgotten. If you don’t design this deliberately, the agent either forgets everything useful or remembers the wrong thing with too much confidence. Neither is acceptable in production.
Layer 4: Signals — What the System Watches
Companies are buying intent data feeds, behavioral datasets, market intelligence packages, all hoping to spot opportunities before competitors do.
Here’s the problem: when everyone buys the same inputs, everyone reaches the same conclusions.
Signals mature through stages:
- Commodity — purchased lists, aggregated feeds (available to everyone)
- Derived — insights computed from public data: job postings, patents, filings
- First-party — internal metrics only you have: usage data, pipeline, ops performance
- Engineered — combinations of datasets plus domain logic, tied to specific outcomes
The last category is where defensible advantage actually lives.
Layer 5: Intent — The Control Loop
You can have prompting, context, memory, and signals all working. Without intent, something critical is still missing: a mechanism to steer toward outcomes rather than just outputs.
Intent engineering treats success as something you define, measure, and verify, not something you hope for. The loop is simple on purpose: define the outcome, define constraints, run the workflow, measure results, improve the system.
This is the real difference between a demo and an operation. Demos create outputs. Operations produce outcomes and can explain when they fail.
How Agents Stop Drifting: Spec-Driven Development
The most reliable AI systems are built against explicit specs. Not vibes. Not “it seems to work.”
A basic agent spec defines:
- Intent — what changes in the real world if this works?
- Inputs — what can it read? Which sources are trusted?
- Constraints — what must it respect, regardless of instructions?
- Tools — what can it touch?
- Verification — what checks must it pass?
- Failure behavior — what does it do when uncertain?
Most teams skip this, then wonder why the agent is inconsistent. If your agent can’t be tested, it can’t be trusted.
What Actually Breaks in Production
Most AI writing focuses on what works. The useful lessons come from what breaks:
✕ Wrong retrieval, confident answer — the system pulls the wrong source and doesn’t know it
✕ Stale truth — internal docs change, the agent keeps citing the old version
✕ Outputs that look right but fail audit — clean formatting, wrong substance
✕ Edge case collapse — works under normal conditions, fails under pressure
✕ Fragile operators — teams that can run the system but can’t diagnose it when something goes wrong
Automation has a long history of creating fragile expertise: people get skilled at operating the system, then lose the underlying ability to catch rare, high-stakes errors. AI is following the same pattern. The mitigation isn’t to slow adoption. It’s to build teams with both domain knowledge and systems fluency.
The Talent Question Behind Every AI Initiative
The most valuable professionals right now are not the ones who “use AI.” Those skills spread quickly, and they already are.
The advantage goes to people who think in systems, not just tasks. You can surface that in interviews:
- How do you turn a messy request into something testable?
- What information would you trust first, and what would you not trust, and why?
- If a tool gives you a clean-looking answer, what checks do you run before trusting it?
- How do you distinguish between analysis and bias introduced by how a question was framed?
- What would you measure every week to know the system is improving, not just producing more output?
These aren’t trick questions. They’re windows into whether someone thinks in systems or just in tasks.
How We Help Companies Acclimate and Thrive in an AI World
Long before “AI roles” became a hiring category, companies needed people who could combine domain expertise, analytical depth, and systems judgment. The titles have changed. The need hasn’t.
That’s the talent ecosystem we focus on at STEM Search Group, across technology, engineering, manufacturing, life sciences, healthcare, and the startups building what comes next.
If AI is going to touch most roles in your organization, you need a recruiting partner who understands how those roles are evolving across every discipline, not just the obvious ones.
Sources:
- Internal Research Paper: The Architecture of Intent: 4 Bricks for the 2026 Professional
- NIST AI Risk Management Framework (AI RMF 1.0) (NIST Publications)
- NIST Generative AI Profile (NIST Publications)
- ISO/IEC/IEEE 29148 Requirements Engineering Standard (ISO)
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (arXiv)
- OWASP LLM Risk Project: Prompt Injection (OWASP Gen AI Security Project)
- OWASP LLM Risk Project: Insecure Output Handling (OWASP Gen AI Security Project)
- EU AI Act (AI literacy and governance) (EUR-Lex)
- Parasuraman & Riley research on automation and human oversight (Massachusetts Institute of Technology)
- OECD Patent Statistics Manual (OECD)
- NBER research on job posting skill signals (NBER)
- “Memory Mechanisms: How AI Agents Remember Your Preferences,” Business Analytics Review (Substack)
- The Architecture of Intent: 4 Bricks for the 2026 Professional
- Lakera AI, The Ultimate Guide to Prompt Engineering in 2026
- Lenny Rachitsky, Five Proven Prompt Engineering Techniques
- Muness Castle, Intent Engineering: From Vibe Coding to Productive Outcomes (Muness Castle)
- Product Compass, The Intent Engineering Framework for AI Agents
- GitHub Blog, Spec-Driven Development with AI: Open Source Toolkit
- GitHub Blog, Agentic AI, MCP, and Spec-Driven Development: Top Blog Posts of 2025
- Gradient Flow, Best Practices in Retrieval Augmented Generation
- Glean, What is Retrieval Augmented Generation (RAG)
- Business Analytics Review, Memory Mechanisms: How AI Agents Remember
- Foster Fletcher, AI Memory Systems Cannot Forget
- Pieces, Best AI Memory Systems
- Blue Morrow, AI Signals Strategic Leaders Strategic Leaders Cannot Ignore (bluemorrow.com)
- Intent Engineering in AI: The Shift Beyond Context Engineering
- From Prompt Engineering to Intent Engineering: The Evolution of Human-AI Communication
- 12 AI Blogs for Keeping Up With AI Trends in 2026 (DigitalOcean) (DigitalOcean)
- Spec-Driven Development with AI: Get Started with a New Open-Source Toolkit (GitHub)
- Best Practices in Retrieval Augmented Generation (GradientFlow)